Research Projects
Object and Scene Segmentation
 |
We address the problem of joint detection and segmentation of multiple object instances in an image, a key step towards scene understanding. Inspired by data-driven methods, we propose an exemplar-based approach to the task of instance segmentation, in which a set of reference image/shape masks is used to find multiple objects. We design a novel CRF framework that jointly models object appearance, shape deformation, and object occlusion. |
Xuming He, Stephen Gould, An Exemplar-based CRF for Multi-instance Object Segmentation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014 [pdf] [Dataset]
Buyu Liu, Xuming He, Stephen Gould, Multi-class Semantic Video Segmentation with Exemplar-based Object Reasoning, IEEE Winter Conference on Applications of Computer Vision (WACV), 2015 [pdf]
Holistic Video Understanding
 |
We address the problem of integrating object reasoning with supervoxel labeling in multiclass semantic video segmentation. To this end, we first propose an object-augmented CRF in spatio-temporal domain, which captures long-range dependency between supervoxels, and imposes consistency between object and supervoxel labels. We develop an efficient inference algorithm to jointly infer the supervoxel labels, object activations and their occlusion relations for a large number of object hypotheses. |
Buyu Liu, Xuming He, Multiclass Semantic Video Segmentation With Object-Level Active Inference, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015 [pdf] [suppl zip]
Buyu Liu, Xuming He, Stephen Gould, Joint Semantic and Geometric Segmentation of Videos with a Stage Model, IEEE Winter Conference on Applications of Computer Vision (WACV), 2014 [pdf]
Depth Prediction from Images
 |
We tackle the problem of single image depth estimation, which, without additional knowledge, suffers from many ambiguities. We introduce a hierarchical representation of the scene and formulate single image depth estimation as inference in a graphical model whose edges let us encode the interactions within and across the different layers of our hierarchy. Our method therefore still produces detailed depth estimates, but also leverages higher-level information about the scene. |
Wei Zhuo, Mathieu Salzmann, Xuming He, Miaomiao Liu, Indoor Scene Structure Analysis for Single Image Depth Estimation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015 [pdf]
Miaomiao Liu, Mathieu Salzmann, Xuming He, Discrete-Continuous Depth Estimation from a Single Image, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014 [pdf]
Object Detection in Context
 |
Exploring contextual relations is one of the key factors to improve object detection under challenging viewing condition and to scale up recognition to large numbers of object classes. We consider two effective approaches that incorporate contextual information: object codetection, which jointly detects object instances in a set of related images, and structural Hough voting, which models the context from 2.5D perspective for object localization under heavy occlusion. |
Zeeshan Hayder, Mathieu Salzmann, Xuming He, Object Co-Detection via Efficient Inference in a Fully-Connected CRF, European Conference on Computer Vision (ECCV), 2014 [pdf]
Tao Wang, Xuming He, Nick Barnes, Learning Structured Hough Voting for Joint Object Detection and Occlusion Reasoning, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013 [pdf] [Dataset]
From Image to Concept
 |
We study basic-level categories for describing visual concepts, and empirically observe context-dependant basic-level names across thousands of concepts. We propose methods for predicting basic-level names using a series of classification and ranking tasks, producing the first large-scale catalogue of basic-level names for hundreds of thousands of images depicting thousands of visual concepts. We also demonstrate the usefulness of our method with a picture-to-word task. |
Alexander Mathews, Lexing Xie, Xuming He, Choosing Basic-Level Concept Names using Visual and Language Context, IEEE Winter Conference on Applications of Computer Vision (WACV), 2015 [pdf] [suppl pdf]
Lexing Xie, Xuming He, Picture Tags and World Knowledge: Learning Tag Relations from Visual Semantic Sources, The 21st ACM International Conference on Multimedia (ACM MM), 2013 [pdf]
Past Projects
Contour Detection and Completion
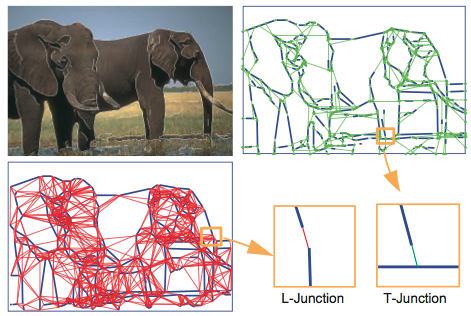 |
|
Image Understanding for Bionic Eye
 |
|
Motion Anlaysis
 |
|
Image/Scene Labeling
 |
|