Software Standards
This section of the development plan suggests standards for developing software in a consistent and logical manner. The primary benefit of adhering to software standards is efficiency. Standards enable each member of a software team to work anywhere in the source code without needing to recognize and adopt a different programming style. More importantly, any programmer can look anywhere in the sources with reliable expectations about how the code will be structured, what objects are, and how to find what they need. In addition, maintenance, revision and shared use of code are simplified. It is crucial to recognize that following one standard consistently is much more important than the details of the standard itself.
Guidelines are suggested in italic throughout this section. They are always open to revision and in instances where they are not followed, a brief comment is usually sufficient to keep other developers informed about what to expect.
This section is structured to be usable as a reference guide as well as providing the underlying motivation for some standards. It is organized as follows: 1.0 introduces formats and practices for source code and user-level documentation; 2.0 describes source code formatting and programming style elements; 3.0 contains standards for structure, maintenance and archival of software systems; and 4.0 lists conventions and suggestions for common tools and utilities.
 1.0
Documentation
1.0
Documentation
"The job's not over `till the paperwork is done!" -- Unknown
Documentation is an integral part of the software development process. Unfortunately, it is all too often treated as an afterthought, sloppily prepared or outright omitted. This is unacceptable for software projects that are being developed jointly by several individuals or those that may be used or maintained by someone other than the original developer. The complex and abstract ideas embodied in most programs must be communicated clearly if there is to be any continuity and efficiency in their development as well as end use. This is certainly true of the user interface which will be operated without the benefit of instruction by the original developers.
Documentation of a software project is organized into several categories:
·
Project
The highest level of software documentation is a description of the purpose and functionality of the entire software system. At this level, the reader should be introduced to the overall problem statement, requirements for an acceptable solution, assumptions made, and important characteristics of the design and implementation of the software such as module interface specifications or resource and timing requirements. The format of project-level documentation varies with size, complexity and external requirements.
·
Module
Many software systems are designed as a collection of interacting modules (or objects), each of which should be documented individually. Most of the criteria listed under project-wide documentation apply to module documentation as well. In addition, a more detailed description of methods, data structures and algorithms should be included. A software requirements specification serves this purpose well.
·
Source Code
Each file of source code should contain comments to aid the reader as well as maintainer in understanding the code. The detailed standards for this level of documentation are described in section 1.1 below.
·
User Level
Documentation intended for the users of a software system must be produced for all but the most trivial programs. The format and contents of user-level documentation depends largely upon the application. Section 1.2 describes common situations and appropriate user-level documentation formats.
1.1 Source Code Documentation
1.1.1 File Comments
Every source code file should begin with a file comment block describing the contents.
Use CVS tracking information; at a minimum, use $Id: software_standards.html,v 1.1 1998/05/21 07:31:07 dsw Exp $ and $:Log:$.
Set a static variable to $Id: software_standards.html,v 1.1 1998/05/21 07:31:07 dsw Exp $ to capture file and version information in object files.
A file comment block should supply at least the following information:
Description
This section provides a brief overview of the file, including its purpose and relevance to the module. If a requirements specification was written, a cross-reference to the pertinent sections should be supplied.
Revision History
The revision history of the file should be maintained to track development and clearly identify authors. This history, listed in reverse chronological order, should contain the date of revision, the revision author, and a detailed list of changes made. CVS provides a mechanism to automatically track revision information. The "$" sign enclosed words, such as $Id: software_standards.html,v 1.1 1998/05/21 07:31:07 dsw Exp $, are keywords used as parameters to be automatically updated. $Log: software_standards.html,v $
Software Standards
This section of the development plan suggests standards for developing software in a consistent and logical manner. The primary benefit of adhering to software standards is efficiency. Standards enable each member of a software team to work anywhere in the source code without needing to recognize and adopt a different programming style. More importantly, any programmer can look anywhere in the sources with reliable expectations about how the code will be structured, what objects are, and how to find what they need. In addition, maintenance, revision and shared use of code are simplified. It is crucial to recognize that following one standard consistently is much more important than the details of the standard itself.
Guidelines are suggested in italic throughout this section. They are always open to revision and in instances where they are not followed, a brief comment is usually sufficient to keep other developers informed about what to expect.
This section is structured to be usable as a reference guide as well as providing the underlying motivation for some standards. It is organized as follows: 1.0 introduces formats and practices for source code and user-level documentation; 2.0 describes source code formatting and programming style elements; 3.0 contains standards for structure, maintenance and archival of software systems; and 4.0 lists conventions and suggestions for common tools and utilities.
1.0
Documentation
"The job's not over `till the paperwork is done!" -- Unknown
Documentation is an integral part of the software development process. Unfortunately, it is all too often treated as an afterthought, sloppily prepared or outright omitted. This is unacceptable for software projects that are being developed jointly by several individuals or those that may be used or maintained by someone other than the original developer. The complex and abstract ideas embodied in most programs must be communicated clearly if there is to be any continuity and efficiency in their development as well as end use. This is certainly true of the user interface which will be operated without the benefit of instruction by the original developers.
Documentation of a software project is organized into several categories:
·
Project
The highest level of software documentation is a description of the purpose and functionality of the entire software system. At this level, the reader should be introduced to the overall problem statement, requirements for an acceptable solution, assumptions made, and important characteristics of the design and implementation of the software such as module interface specifications or resource and timing requirements. The format of project-level documentation varies with size, complexity and external requirements.
·
Module
Many software systems are designed as a collection of interacting modules (or objects), each of which should be documented individually. Most of the criteria listed under project-wide documentation apply to module documentation as well. In addition, a more detailed description of methods, data structures and algorithms should be included. A software requirements specification serves this purpose well.
·
Source Code
Each file of source code should contain comments to aid the reader as well as maintainer in understanding the code. The detailed standards for this level of documentation are described in section 1.1 below.
·
User Level
Documentation intended for the users of a software system must be produced for all but the most trivial programs. The format and contents of user-level documentation depends largely upon the application. Section 1.2 describes common situations and appropriate user-level documentation formats.
1.1 Source Code Documentation
1.1.1 File Comments
Every source code file should begin with a file comment block describing the contents.
Use CVS tracking information; at a minimum, use $Id:$ and $:Log:$.
Set a static variable to $Id:$ to capture file and version information in object files.
A file comment block should supply at least the following information:
Description
This section provides a brief overview of the file, including its purpose and relevance to the module. If a requirements specification was written, a cross-reference to the pertinent sections should be supplied.
Revision History
The revision history of the file should be maintained to track development and clearly identify authors. This history, listed in reverse chronological order, should contain the date of revision, the revision author, and a detailed list of changes made. CVS provides a mechanism to automatically track revision information. The "$" sign enclosed words, such as $Id$, are keywords used as parameters to be automatically updated. Revision 1.1 1998/05/21 07:31:07 dsw
Software Standards
This section of the development plan suggests standards for developing software in a consistent and logical manner. The primary benefit of adhering to software standards is efficiency. Standards enable each member of a software team to work anywhere in the source code without needing to recognize and adopt a different programming style. More importantly, any programmer can look anywhere in the sources with reliable expectations about how the code will be structured, what objects are, and how to find what they need. In addition, maintenance, revision and shared use of code are simplified. It is crucial to recognize that following one standard consistently is much more important than the details of the standard itself.
Guidelines are suggested in italic throughout this section. They are always open to revision and in instances where they are not followed, a brief comment is usually sufficient to keep other developers informed about what to expect.
This section is structured to be usable as a reference guide as well as providing the underlying motivation for some standards. It is organized as follows: 1.0 introduces formats and practices for source code and user-level documentation; 2.0 describes source code formatting and programming style elements; 3.0 contains standards for structure, maintenance and archival of software systems; and 4.0 lists conventions and suggestions for common tools and utilities.
1.0
Documentation
"The job's not over `till the paperwork is done!" -- Unknown
Documentation is an integral part of the software development process. Unfortunately, it is all too often treated as an afterthought, sloppily prepared or outright omitted. This is unacceptable for software projects that are being developed jointly by several individuals or those that may be used or maintained by someone other than the original developer. The complex and abstract ideas embodied in most programs must be communicated clearly if there is to be any continuity and efficiency in their development as well as end use. This is certainly true of the user interface which will be operated without the benefit of instruction by the original developers.
Documentation of a software project is organized into several categories:
·
Project
The highest level of software documentation is a description of the purpose and functionality of the entire software system. At this level, the reader should be introduced to the overall problem statement, requirements for an acceptable solution, assumptions made, and important characteristics of the design and implementation of the software such as module interface specifications or resource and timing requirements. The format of project-level documentation varies with size, complexity and external requirements.
·
Module
Many software systems are designed as a collection of interacting modules (or objects), each of which should be documented individually. Most of the criteria listed under project-wide documentation apply to module documentation as well. In addition, a more detailed description of methods, data structures and algorithms should be included. A software requirements specification serves this purpose well.
·
Source Code
Each file of source code should contain comments to aid the reader as well as maintainer in understanding the code. The detailed standards for this level of documentation are described in section 1.1 below.
·
User Level
Documentation intended for the users of a software system must be produced for all but the most trivial programs. The format and contents of user-level documentation depends largely upon the application. Section 1.2 describes common situations and appropriate user-level documentation formats.
1.1 Source Code Documentation
1.1.1 File Comments
Every source code file should begin with a file comment block describing the contents.
Use CVS tracking information; at a minimum, use $Id:$ and $:Log:$.
Set a static variable to $Id:$ to capture file and version information in object files.
A file comment block should supply at least the following information:
Description
This section provides a brief overview of the file, including its purpose and relevance to the module. If a requirements specification was written, a cross-reference to the pertinent sections should be supplied.
Revision History
The revision history of the file should be maintained to track development and clearly identify authors. This history, listed in reverse chronological order, should contain the date of revision, the revision author, and a detailed list of changes made. CVS provides a mechanism to automatically track revision information. The "$" sign enclosed words, such as $Id$, are keywords used as parameters to be automatically updated. Added software architecture and standards.
Software Standards
This section of the development plan suggests standards for developing software in a consistent and logical manner. The primary benefit of adhering to software standards is efficiency. Standards enable each member of a software team to work anywhere in the source code without needing to recognize and adopt a different programming style. More importantly, any programmer can look anywhere in the sources with reliable expectations about how the code will be structured, what objects are, and how to find what they need. In addition, maintenance, revision and shared use of code are simplified. It is crucial to recognize that following one standard consistently is much more important than the details of the standard itself.
Guidelines are suggested in italic throughout this section. They are always open to revision and in instances where they are not followed, a brief comment is usually sufficient to keep other developers informed about what to expect.
This section is structured to be usable as a reference guide as well as providing the underlying motivation for some standards. It is organized as follows: 1.0 introduces formats and practices for source code and user-level documentation; 2.0 describes source code formatting and programming style elements; 3.0 contains standards for structure, maintenance and archival of software systems; and 4.0 lists conventions and suggestions for common tools and utilities.
1.0
Documentation
"The job's not over `till the paperwork is done!" -- Unknown
Documentation is an integral part of the software development process. Unfortunately, it is all too often treated as an afterthought, sloppily prepared or outright omitted. This is unacceptable for software projects that are being developed jointly by several individuals or those that may be used or maintained by someone other than the original developer. The complex and abstract ideas embodied in most programs must be communicated clearly if there is to be any continuity and efficiency in their development as well as end use. This is certainly true of the user interface which will be operated without the benefit of instruction by the original developers.
Documentation of a software project is organized into several categories:
·
Project
The highest level of software documentation is a description of the purpose and functionality of the entire software system. At this level, the reader should be introduced to the overall problem statement, requirements for an acceptable solution, assumptions made, and important characteristics of the design and implementation of the software such as module interface specifications or resource and timing requirements. The format of project-level documentation varies with size, complexity and external requirements.
·
Module
Many software systems are designed as a collection of interacting modules (or objects), each of which should be documented individually. Most of the criteria listed under project-wide documentation apply to module documentation as well. In addition, a more detailed description of methods, data structures and algorithms should be included. A software requirements specification serves this purpose well.
·
Source Code
Each file of source code should contain comments to aid the reader as well as maintainer in understanding the code. The detailed standards for this level of documentation are described in section 1.1 below.
·
User Level
Documentation intended for the users of a software system must be produced for all but the most trivial programs. The format and contents of user-level documentation depends largely upon the application. Section 1.2 describes common situations and appropriate user-level documentation formats.
1.1 Source Code Documentation
1.1.1 File Comments
Every source code file should begin with a file comment block describing the contents.
Use CVS tracking information; at a minimum, use $Id:$ and $:Log:$.
Set a static variable to $Id:$ to capture file and version information in object files.
A file comment block should supply at least the following information:
Description
This section provides a brief overview of the file, including its purpose and relevance to the module. If a requirements specification was written, a cross-reference to the pertinent sections should be supplied.
Revision History
The revision history of the file should be maintained to track development and clearly identify authors. This history, listed in reverse chronological order, should contain the date of revision, the revision author, and a detailed list of changes made. CVS provides a mechanism to automatically track revision information. The "$" sign enclosed words, such as $Id$, are keywords used as parameters to be automatically updated. incorporates a running log of changes into the comments. For more information on CVS, see section 4.2
Exports
Every function and variable (method and object) made globally available should be explicitly listed in this section and followed by a short descriptive statement. This serves as a summary of the file's interface to the rest of the software system. See section 2.2 for rules regarding the scope of functions and variables.
1.1.2 Function Comments
All functions within a source file should be preceded by a function comment block which explains the purpose of the function and all its direct and side effects.
Do something to delineate function breaks, for example a line of "/*******/".
Each function should begin on a new page (which is achieved by inserting an ASCII formfeed, ^L, before the comment block) unless a few short functions can be grouped on one page.
/********************************************************
* DESCRIPTION: Use pose information to command rendering
* rendering of robot model in the new position
* INPUTS: robotPose - Robot position and orientation
* robotConfig - Robot internal configuration
* RETURNS: True if rendered, False otherwise
********************************************************/
The function comment block should at minimum contain the following two fields:
Description
A textual explanation of what the function does. If a requirements specification was written, refer to the specific requirements that are satisfied by this function.
For most functions, one or more of the following fields is appropriate in the function comment block:
Globals
The global variables referenced by the function (see section 2.6). This may be obviated by explicitly externing the globals within C++ methods.
Outputs
Most important, list any variables changed by pointer de-referencing. This means, even if the pointer to a struct does not change, make explicit whether the structure changes.
1.1.3 In-Line Comments
An in-line comment is descriptive text appearing immediately before, after, or next to a section of source code. In-line comments are intended to guide the reader through an algorithm, explain the reasoning behind a statement that may not be obvious, or explicitly state assumptions made at a particular point in the program.
Keep the "*" (or if C++, the "//") aligned on the left.
Do not use right justified comments to make boxes. They waste a lot of time.
Comments must be easily visible. When documenting a variable or parameter declaration, comments should be placed on the same line as the declaration, and subsequent comments of this type should be aligned vertically. Some examples:
int renderCount; /* Counter for number of renderings */
float robotX; /* Robot's global X coordinate */
class robotConfig; // Robot model object
* Multi-line comments are typically used for complete sentences.
* The leading "/*" and trailing "*/" sequences should be on a
1.1.4 README Files
Provide README files as a roadmap to the directories and files in the current directory and subdirectories.
README files are a convenient mechanism to provide a starting point for documentation of a software package. Provide one README file for each directory whose contents aren't obvious. For instance, top-level directories and "src" directories should have a README file.
The contents of a README file should: provide an overview of what the files in this directory do; describe how to build the executables and explain makefile targets; point out known problems, anomalies, side effects or caveats; and list documents that contain further information.
1.2 User Level Documentation
The purpose of user level documentation is to allow individuals other than the developers to run the software. In fact, for complex programs it is often useful even for the original authors of the code to have a reference guide on how to invoke and operate the program. An efficient and universally accepted method for such a reference is an entry in the Unix Programmer's Manual, a.k.a. "man page". Other operating systems provide similar on-line manuals.
Every program intended to be invoked by a human user from a Unix shell should be documented in a man page.
At a minimum, a man page should give an overview of what the program does and document all applicable command line options and their effects. Typical sections of man pages, as well as information on how to create them, can be found in section 4.3.
A common problem that occurs during the development phase of software systems is that only the authors of individual modules know how to run their programs. To avoid the necessity of having all programmers present to run a complex software system, generation of man pages should not be left until after the program is completed.
Write a software requirements specification and design document before implementing code. The information in these documents can be quickly translated into man pages.
1.2.1 Libraries
Libraries of utilities or self-contained packages can also be documented with man pages, although it is sometimes more appropriate to produce a User's Guide with a word-processing program. Use common sense in deciding on a format, keeping in mind who the target audience is and how to communicate the relevant information effectively. Users of libraries are typically application programmers, who will initially need to read an overview of the library. Subsequently, they will require a reference guide periodically to look up detailed information on specific elements of the library. A table of contents and alphabetized index is essential.
2.0
Coding Style
2.1 Compilation
All code should follow ANSI C and C++ standards.
Use of ANSI C++ standards enables automatic checking for proper usage of procedure calls to external functions, as well as tightening up of a lot of loose ends in traditional C. A common compiler is specified in order to avoid any problems in linking between object modules and libraries.
2.2 Scope and Definitions
All function and variable types should be explicitly defined, including those of type "void" and "int", but excepting class constructors and destructors.
Functions and variables of local scope (used only within the file) should be declared as static. By implication, functions and variables not declared static are intended to be globally available.
This practice minimizes the number of functions and variables seen globally across files during linking, and improves modularity of the software.
2.3 Indentation
A tab character, when used, will always move the cursor to the next column which is a multiple of eight spaces.
No line must be longer than 79 characters unless absolutely necessary.
The above two rules improve printability of the source code. Most printers and editors truncate lines to 79 characters, and assume that a tab always moves the cursor to a column which is a multiple of eight spaces.
The number of spaces to use for indentation is up to the programmer. However, files which contain tab characters must assume that they will be interpreted as eight space tab stops. This ensures that programs will look the same when viewed with different editors or printed with different code formatters. If you do not want to indent your code in eight space increments, you must insert space characters. For example, if your preference is to indent by 4 spaces, 4 space characters must be inserted for the first level of indentation. However, the next tab stop may contain a tab character (moving the cursor to the eighth space), or four more spaces. Note that most editors like emacs can be configured to do all of this automatically.
2.4 Braces
Follow the Kernighan and Ritchie method of brace alignment.
Use braces even when blocks of code contain only a single line.
Functions are marked by braces on separate lines, whereas all other blocks begin with a brace on the same line as the conditional. It is recommended that single line blocks also be marked by braces. This is considered good style since it prevents the programmer from later adding a line to the conditional while forgetting to add braces. A code fragment using this method looks like:
2.5 Identifier Naming Style
Consistent use of a naming style for identifiers significantly improves code readability, allowing new programmers to easily determine the kind of identifier being referred to (macro, typedef, variable or function) and to get an idea of where to find the declaration of that identifier. The goal of the following rules and guidelines is to distinguish between different classes of identifiers by dictating the use of upper and lower case, underscores and suffixes.
2.5.1 Functions
The first letter of each word in the function name will be in Upper case. Words will be distinguished by initial capitals but not underscores or hyphens.
The first word of all exported functions will be a common name or acronym identifying the declaring module.
There are two purposes behind these conventions. One is to prevent name clashes that can arise when linking together modules written by different people. The other is to help locate the declarations of functions and provide a context for readability. For example, a function named SimUpdateDisplay() provides an obvious hint as to the context of the display update operation in question.
2.5.2 Variables
The first word of every variable name will be in lower case. Any additional words will be distinguished from the first word by initial capitals.
In C, all static variable names will be post-fixed with "Static" and all global variable names will be post-fixed with "Global."
The first word or letters of exported variables and functions (objects and methods) should be the same to identify the declaring module.
In C, variables are treated much like functions: you can assign a variable to a function or pass a function as a variable. Therefore the two are treated similarly.
The following declarations are valid:
int controlSemaphoreGlobal; /* An exported global variable*/
static int errorValueStatic; /* A local variable */
void controlMove(void); /* A global function */
extern controlSemaphoreGlobal;
float robotX, robotY, robotYaw;
2.5.3 Macros
All macros must be in all-caps, with underscores separating multiple words.
#define DEGREES_OF_FREEDOM 1776
In C++, never use macros, instead use consts for constants and inline functions (which allow type checking) for short calculations.
2.5.4 Types
All typedefs should be in all-caps, with underscores separating multiple words. In addition, suffixes will be appended indicating one of four categories: "_ARRAY" for arrays, "_PTR" for pointers, "_ENUM" for enumerated types, and "_TYPE" for everything else.
The first word of elements of an enumerated type will start with an uppercase letter followed by lower case letters. Any additional words will be distinguished from the first word by initial capitals.
Typedefs are similar to macros and are therefore subject to the same capitalization rules. Recursive data structures will use the same type name preceded by an underscore for their declaration.
Enumerated types are essentially a type declaration and several macros definitions combined. The only difference is that the type specification of an enumerated type is followed by _ENUM rather than _TYPE.
2.6 Global Variables
Global variables must be fully documented as to purpose, what modules access the variable, and under what conditions access occurs.
Use static variables and access functions for modifying their values instead of global variables whenever possible.
If using C++, consider implementing a class with private data and public methods for accessing and modifying the data.
The use of global variables should be minimized to justifiable cases. Global variables are difficult to debug and hard to understand when looking through someone else's code. Most often, they can be replaced by static variables and access functions for modifying their values. This method restricts access to them to specific functions and facilitates the use of "stop in <function>" when debugging with dbx.
An example of a static variable with access functions (in the file status) is as follows:
static int currentStatusStatic;
/* Error checking on value... */
In the case where efficiency is vital, global variables will be tolerated provided they are appropriately documented (see section 2.6 on page 7).
2.7 Header Files
2.7.1 Contents
Header files (ending with the ".h" suffix) should contain only macros, consts, type (and class) definitions, external functions, or external variable declarations.
All exported functions and variables should be declared in a header file.
Public header files (those installed into the public include directory) will be as minimal as possible. ONLY those macros, types and external function headers needed to access the module are to be declared. Definitions internal to a module should be put in a separate file.
Under no circumstances should any kind of data storage or actual code be declared in a header file. For obvious reasons, comments are as appropriate in header files as in source code files. Macros or type definitions local to a single source file may reside within that source file if they are reasonably small in number.
2.7.2 Nested Inclusion
Nested inclusion protection should be incorporated into every header file.
It is permitted to nest inclusion of header files; this can alleviate constraints on the ordering of #include statements in source files. However, if this technique is used, care must be taken to avoid multiple inclusion of the header files, which will lead to compiler warnings. A common mechanism to prevent this is to bracket the entire body of a header file with the following statements:
#ifndef INCheaderfileh
#define INCheaderfileh
/* Body of Header File */
#endif INCheaderfileh
The macro name - "INCheaderfileh" in the above example must be unique for each header file, and is usually formed by pre-pending "INC" to the file name and removing the period.
3.0
Directory Structure
The purpose of a directory hierarchy is to group files in a logical fashion according to their purpose. The goal of standardizing structure is to avoid having to untangle cross references and file dependencies that can result from using an ad-hoc structure.
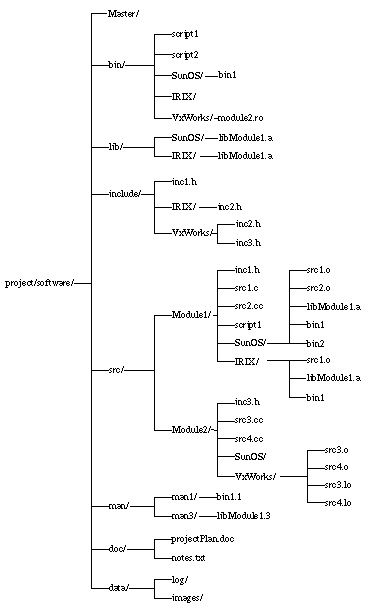
Figure 3-1 suggests a typical project directory structure. Often a home directory is established which contains subdirectories named software, hardware, members and possibly others. This discussion focuses on the structure of the software subdirectory.
|
A detailed explanation and guidelines for use of the individual directory types is given in sections See Master Directory through See Data Directory . The following rules govern the overall structure:
The top level directory of a software project contains eight subdirectories: Master , bin , lib , include , src , man , doc , and data .
It is strongly suggested that no other directories or files be created at the top level; all software files should reside under one of these subdirectories. Allowing other directories at this level would defeat the purpose of a standard directory structure.
The software project directory should always contain the most recent or most functional version of the software.
Only code that is reasonably stable should be deposited in the software directory. This way, project team members know where to find usable code developed by other team members without having to look through personal workspaces of others. At the very least, the makefiles should be set up correctly and all code should compile and run.
Maintain a personal workspace with a set of the standard directories and use CVS to maintain copies of all files you need to modify.
Once you have a working version of your code, commit it with CVS and update the project directory. At this time you can "make install" in the project src directory to compile and install the header files, libraries, etc. into the appropriate places.
Source code should be developed and edited in personal work spaces.
When a stable version of the source files has emerged, they are deposited into the project directory's src, doc or data directory, as appropriate. Compilation is then performed in the src directory, followed by installation into bin, include, lib and/or man (see below for more details on installation).
Only the src , doc and data directories contains files created by developers.
The src directory is the location of the primary source for software and manual pages, which is generated by the programmer. This forces related files to exist together in a single directory, making maintenance and revision simpler than having to track multiple directories. Furthermore, this enables the programmer to use CVS to maintain complete revisions of source files, header files and manual pages by maintaining a single directory. Using standard Makefiles makes installation of these files efficient.
The doc and data directories contain documentation and data files which are typically neither subject to revision control nor generated from sources; thus they are updated directly by the programmer.
All files found in bin , lib , include and man are installed by copying corresponding files from within the src directory hierarchy.
Object code (executables and libraries) is compiled in the src area from source files and installed in bin or lib. Header files to be shared with other modules are installed in the include directory hierarchy, and manual pages are installed in the appropriate man subdirectory.
None of the files in bin , include , lib and man should have write permission for anyone, including the owner.
Note that the directories will have write permission, but the files will not. This prevents accidental modification of installed copies of files since the files will not be editable. However, the directory has write permission which allows a programmer to delete or install files into these directories. This helps enforce the rule that you must work in the src directory and install copies of the files in src into bin, include, lib and man.
3.1 Master Directory
The Master directory is the CVS repository of the entire software project. It is imperative that there be only one single Master directory.
The contents of the Master directory should only be accessed via CVS utilities.
Under normal circumstances, programmers shouldn't have to examine or change anything in the Master directory, since its contents are managed by the CVS tools.
3.2 Bin Directory
The bin directory contains only executable scripts and operating system subdirectories, which in turn contain executable programs.
The bin directory contains all executable programs generated by the project. All corresponding source files must be located under the src hierarchy, even if they are scripts that are installed by simply copying them to the bin directory.
In Figure 3-1 , the bin directory contains a script copied from src/Module1, operating system dependent executable, bin1, and real-time runnable object module2.ro.
3.3 Lib Directory
The lib operating system subdirectories contain libraries and object files to be shared across modules.
The lib directory contains only compiled object files or library archives; no other types of files are allowed. The corresponding source files should be located under the src hierarchy.
The lib operating system subdirectories may contain subdirectories for a module of libraries and object files to be shared within that module.
Only if necessary, for example with a module that consists of many submodules, a module may install, to a subdirectory, private libraries shared among its submodules. A subdirectory under lib should have the same name as the corresponding module directory under src.
In figure Figure 3-1 , the archive libModule1.a may be linked by any module under src.
3.4 Include Directory
The include directory contains header files to be shared across modules.
The include directory contains all the header files needed when using the object modules and library files located in lib . No other types of files are allowed.
The include directory may contain subdirectories. These subdirectories contain header files to be shared among submodules of a single module.
The same scope rules stated for subdirectories under lib apply to the include hierarchy.
3.5 Src Directory
All source code files, header files and manual pages will reside in the src directory.
All libraries and executables will be created by compiling the files in the src directory.
The src directory contains all the source files necessary for generating the bin , include, lib, and man directories. The src directory is considered to be private, in the sense that the general user should never have to go into src in order to run an executable, look up a man page, link a library, or search for documentation. All files necessary for public reference are to be located in bin, include, lib, doc and man . There are only two reasons to go into the src directory: to create or update source files, header files or manual pages; or to examine source files because a bug is suspected or to find out "how things work".
Do not work directly in the project src directory`
Its contents may be overwritten by another person at any time and your changes may introduce a bug that would affect others. The src directory is to be used only for "publishing" reasonably stable code, and for compiling and installing the new code into the bin, man, etc. directories. Work in your private source directory and use CVS to update the project release area.
A source file should include header files from only:
The current working directory
The project include directory (/project/include/*.h)
The module include subdirectory (/project/include/module/*.h)
The project include operating system subdirectory (/project/VxWorks/include/*.h)
Non-project related include directories (/usr/local/include).
An object file should be linked with object code from only:
Object files compiled in the current working directory
Libraries in the project library directory (/project/lib/*.a)
Libraries in the project library operating system subdirectory (/project/lib/IRIX/*.a)
Libraries in the module library subdirectory (e.g. project/lib/module/*.a)
Non-project related libraries (e.g. /usr/lib/libX11.a)
The files in the src directory should never depend on header or library files in another src directory.
Figure 3-1 shows a project that consists of two modules. In the example, both Module1 and Module2 are simple and do not contain submodules, hence there are no there is no Module1 or Module2 subdirectory in the inc or lib directories.
3.6 Man Directory
The man directory must conform to the standard UNIX man directory format.
As files get put into bin and lib , generate the corresponding man pages and install them in man .
The man directory will contain only subdirectories of the format man<n> and cat<n>, and the special file whatis. The "<n>" represents the section of the manual, which is typically a number between 1 and 8. The manual sections applicable to project-generated software are:
· man1: User Commands - These correspond to executables in the bin directory.
· man3: Subroutines - Man pages describing libraries in the lib directory.
· man5: File Formats - Definitions of data file formats found in the data directory.
In the example in Figure 3-1 , the man directory contains subdirectories for sections 1 and 3 of the manual. man1 contains a man page for the program bin1, while man3 contains a man page describing the library libModule2.a
The cat<n> directories contain the pre-formatted versions of the corresponding files in their man<n> counterparts, which speeds up on-line display of man pages. See catman(8) for more information. The file whatis is also generated by the catman program and provides keyword lookup functionality.
3.7 Doc Directory
The doc directory contains documents related to the code in the src directory only.
Create subdirectories under doc to organize documents in a logical fashion.
The doc directory is a place for any additional documents related to the body of code in this directory tree. Academic papers, design documents, proposals or notes are all examples of documents that might reside here. A running log of bug reports might also be archived under this directory.
3.8 Data Directory
The data directory contains configuration files, log files, etc. used by the programs in bin.
The data directory is an area intended for files referenced by the software system at run-time, such as data output logs and input parameters of experiments, session logs, kinematic configuration data and system state files.
4.0
Tools and Utilities
4.1 Makefiles
Makefiles are required for compilation of source files as well as for generation and installation of libraries, include files, executables and documentation into their designated public directories. In general, most users experience problems with makefile incompatibility when executing different versions of make . It seems that each version of make has its own idiosyncrasies.
The goal in setting up the following makefile standards are twofold. First, adoption of a standard itself will allow increased proficiency in being able to decipher another person's makefile. Second, the standard makefile will be tolerant of idiosyncrasies across different versions of make . Developers that customize makefiles should do so in a way that will not defeat these two goals.
All makefiles will be named "Makefile," with a capital `M'.
This is a default name assumed by many programs, including GNU make, and visibly distinguishes the makefile from source files which typically start with a lowercase letter.
All makefiles will have at least the following targets defined: all, install, and clean. Performing a "make all" must be equivalent to performing a "make."
all
Usually, "all" is the first target specified. Make makes this target (the first one) when no targets are specified on the command line. Typically, this target will generate all library files, object files, and executable files associated with the source files in the current directory. This target should not install files into the public directories.
install
This target will install all files to be used by the public into the public directories. Object and library files go into lib, header files go into include, executable files go into bin, man pages to man. The install target should make all first.
4.2 CVS
CVS is a package that offers great convenience to the programmer. CVS keeps a single copy of the most recent master sources. This copy is called the source "repository;" It contains all the information to permit extraction of previous releases at any time based on a user-specified tag of time, date, etc. The user gets files from the repository and places them in his local workspace where he can then change the files. If the change is satisfactory, he can "publish" the change. CVS also allows for multiple users to modify a file. It also provides for the retrieval of old releases.
4.3 Manual Page Formatting
Unix manual pages are troff(1)/nroff(1) formatted documents that can be printed or viewed on-line with the man(1) or xman(1) program. To create a manual page, the doc(1) program can be used, or the troff source file can be edited directly. While neither are attractive choices, no alternatives are known at this time.
The typical Unix manual page consists of the following sections described in /usr/man/man7/man.7.