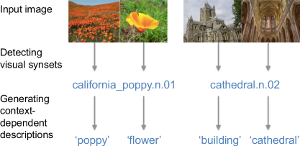
We study basic-level categories for describing visual concepts, and empirically observed context-dependant basic-level names across thousands of concepts. We propose methods for predicting basic-level names using a series of classification and ranking tasks, producing the first large-scale catalogue of basic-level names for hundreds of thousands of images depicting thousands of visual concepts. We also demonstrate the usefulness of our method with a picture-to-word task, showing strong improvement (0.17 precision at slightly higher recall) over recent work by Ordonez et al, and observing significant effects of incorporating both visual and language context for classification. Moreover, our study suggests that a model for naming visual concepts is an important part of any automatic image/video captioning and visual story-telling system.
We have also released our training datasets and our testing dataset (SBU-148K), which are derived from the SBU dataset. Our release consists of flickr ids, matching those in the SBU dataset, paired with the filtered list of nouns extracted from the image caption. The dataset is available here as an archive containing pickle files.
For comparison purposes a full set of results is available here. This dataset also includes: the most frequent noun for each synset, synset detections for the testing set and the results used to generate Figure 3 (in the paper).