
|
|
|
|---|
An objective data set introduced by Doron Witztum is analysed using the method defined by Doron Witztum.
The result of 1 in a million claimed by Doron Witztum on Israeli television is shown to be only two hundred and eighty-nine thousand times too small.
As faithful disciples of Doron Witztum, we have learned from him the need for objectivity and consistency. Consequently, we will perform this experiment exactly as specified by him. This commandment is enshrined in the following sacred rules.
We are motivated by outrage over the recent attacks on Doron Witztum by the Great Pretender, Michael Drosnin. For example:
It should be plain to everyone that such attacks are totally without foundation. Doron Witztum's work is a model of objective scientific research, light years ahead of Drosnin's pathetic manipulations.
For inspiration we turned to the press statement issued by our Teacher on June 4, 1997. In there we read:
More details of this wonderful experiment were presented on the highly intellectual discussion program Popolitika, shown on Israeli television on June 16, 1997. In response to a disgraceful attack from Maya Bar-Hillel, our Teacher made the following statement:
 Let me show you how it works... You don't have to... I'll show you...
I am now specifically relating to how it works...
Watch this example, you asked how it works,
well watch this example... Please, you haven't heard me out. How do you
know if this is relevant? Please, you see here, I want to take a subject,
for example, the subject of Auschwitz, how I investigate the subject. I
open the Hebrew Encyclopedia, the entry for Auschwitz, I open the Encyclopedia
of the Holocaust, the entry for Auschwitz, I wanted an objective set of
words related to the concept of Auschwitz, and I came across this table
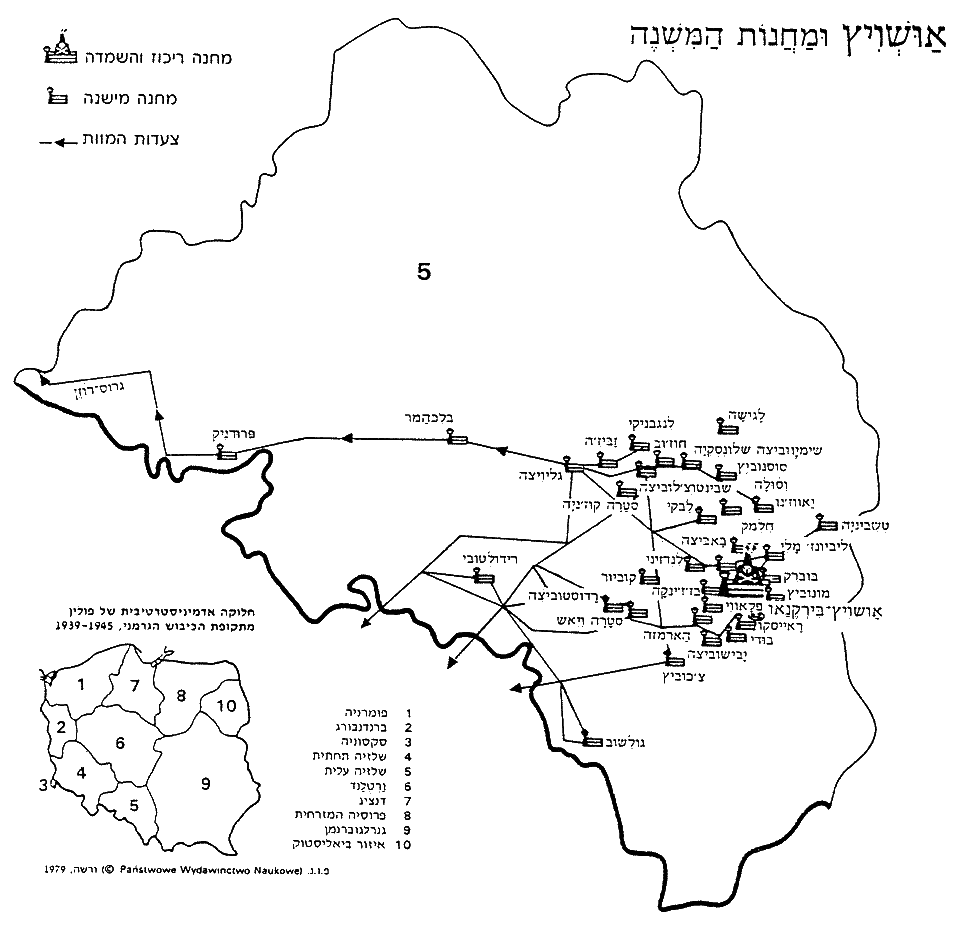
[pointing to a map as shown here - click it for a larger picture]
of Auschwitz and its sub-camps. This contains an organized list of all
the sub-camps, they are not all here, there are others listed in
parallel entries. I take a title "Be'Auschwitz" and
search for a sub-camp or secondary camp of Auschwitz. These are the
words that... I am now shooting at a target while blindfolded... everything
here happens by coincidence... I shoot this objective list of names...
The success is one in a million... totally objectively.
Let me show you how it works... You don't have to... I'll show you...
I am now specifically relating to how it works...
Watch this example, you asked how it works,
well watch this example... Please, you haven't heard me out. How do you
know if this is relevant? Please, you see here, I want to take a subject,
for example, the subject of Auschwitz, how I investigate the subject. I
open the Hebrew Encyclopedia, the entry for Auschwitz, I open the Encyclopedia
of the Holocaust, the entry for Auschwitz, I wanted an objective set of
words related to the concept of Auschwitz, and I came across this table
[pointing to a map as shown here - click it for a larger picture]
of Auschwitz and its sub-camps. This contains an organized list of all
the sub-camps, they are not all here, there are others listed in
parallel entries. I take a title "Be'Auschwitz" and
search for a sub-camp or secondary camp of Auschwitz. These are the
words that... I am now shooting at a target while blindfolded... everything
here happens by coincidence... I shoot this objective list of names...
The success is one in a million... totally objectively.We could hardly wait to see this result with our own eyes, so we hurried to the library and found the Encyclopedia of the Holocaust. There, in the very place our Teacher predicted, was that very map. We noted with satisfaction that he had chosen the map from the Hebrew edition of the Encyclopedia, in order to avoid the subjectivity of cross-language transliteration.
Our Teacher has taught us several important lessons.
Consequently, our experiment has the title phrase
![]() (of Auschwitz) spelt exactly as it is spelt twice on the map
(plus the preposition B). We note without surprise that "of Auschwitz"
is spelt in precisely the same manner in our Teacher's 1989 book.
(of Auschwitz) spelt exactly as it is spelt twice on the map
(plus the preposition B). We note without surprise that "of Auschwitz"
is spelt in precisely the same manner in our Teacher's 1989 book.
As related phrases, we have the names of the 32 sub-camps, spelt as on the map. Here they are, together with the names given in the English edition of the Encyclopedia.

Armed with our Teacher's totally objective data, we studied his method for calculating a rigorous significance level. It is defined in detail in his masterpiece [WRR3], which was applauded by the Israeli Academy of Sciences.
We followed our Teacher's instructions with reverent care. First we rejected all the words with less than 5 or more than 8 letters, as well as those having no ELS in Genesis. There were 13 sub-camps remaining: numbers 2, 4-6, 10, 11, 18, 20-22, 26, 27, and 32. Then we measured the distance of each of those sub-camps from the title word "of Auschwitz" and combined the 13 distances into a single value that our Teacher calls "P2". (In passing, we recalled with disdain the totally false allegation that our Teacher used to think P2 was a probability.) Then we randomly shuffled the letters of the sub-camp names, and calculated P2 again.
The shuffling and measuring was repeated one million times, then all the P2 values were compared to the original P2 value. Our Teacher had said that the original value would be smaller than most or all of the others, showing that the sub-camps of Auschwitz were definitely encoded in the Book of Genesis.
Finally the computation had finished, and we had our answer: 289149 out of a million!
How can we express our pleasure? Sure, there were 289148 permuted samples which did better than the original, but what is that compared to the 710851 which did worse? Who can doubt the Codes now??
In this section we leave the jokes behind and consider what can be learned from this example.
Yes and no. As far as lists of sub-camps of Auschwitz are concerned, it would be hard to be more objective than this. The choice of sub-camps to include, and how to write them in Hebrew, was performed by an independent expert with no interest in codes (as far as we know). Yet even here Doron Witztum had plenty of choice. He didn't have to choose Auschwitz, as lists of the sub-camps of Dachau, or Buchenwald, or many other major camps are also available. He didn't have to choose the Encyclopedia of the Holocaust either, as alternative lists appear in other places. They are probably all different in at least some aspects except where they are copied from the same source.
In other words, even for this most objective aspect of the experiment, there was a considerable amount of choice available. One can conservatively estimate that 50 lists of similar nature exist just for the topic "sub-camps of a Nazi concentration camp". Of course, we have no way to know how many were considered by Doron Witztum.
There was also no need to choose sub-camp names as the list of related expressions. He could have chosen the names of the major communities that were deported to Auschwitz, the names of the senior Nazi officers at Auschwitz, or several other things. We know that Witztum has previously explored the subject of Auschwitz in great detail, so there is no reason to believe he chose sub-camps as the topic without prior knowledge.
In summary, even though the data set we used is the most objective we ever saw Doron Witztum define, the very act of choosing it involved considerable freedom of choice. One can say that there are at least hundreds, if not thousands, of alternative choices available.
The title word "be'Auschwitz" is another big problem, because it is wrong. "Be'Auschwitz" doesn't mean "of Auschwitz" at all; it means "in Auschwitz". The phrase "of Auschwitz" is usually written in Hebrew as "shel Auschwitz". We have two ways of knowing he didn't use that. First because he clearly said "be'Auschwitz" on Popolitika, and second because "shel Auschwitz" doesn't have an ELS in Genesis.
Is "be'Auschwitz" acceptable anyway? No, it isn't. Only the very few central camps, such as Birkenau and Monowitz, might be said to be in Auschwitz. The others were far way, even more than 100km away. It is like saying that the Australian trade office in New Zealand is "in Australia".
The best hope for an excuse is that the camps were all "in the Auschwitz sub-camp system", or some similar construction. The problem with that excuse, of course, is that it isn't what "be'Auschwitz" means.
In any case, the proof that Doron Witztum knows "be'Auschwitz" is wrong is right there near the start of this document. If he really thought "in Auschwitz" was the right description, why did he mistranslate it as "of Auschwitz" in the press release?
The use of prepositions and articles to tweak the data is an old trick of Doron Witztum. The most objective, and only really natural title word in this case, is "Auschwitz". It fails miserably: 205767 in a million. Another common spelling of the word, with an extra waw, scores 351003 in a million.
The most likely answer, perhaps surprisingly, is "yes". We are confident that he has some data, and some calculation method, that give a strong result. We have no idea what it is, except that either it isn't this data or it isn't this method. Very likely he changed both.
This is the category in which Witztum is the most practised. To our knowledge, he has never taken data from a simple, well-defined source in the most obvious manner. The number of games that could be played with the data in the present experiment is truly huge, so we will simply list a few.
Note that in each case where there is a choice between two
alternatives, we also have the option of impressing our readers with
our even-handedness by choosing both if that is to our advantage.
Sometimes we might, alternatively, be able to argue "we cannot
determine which is the most correct, so we will use neither".
Then, of course, we can try applying some set of "objective" spelling rules, maybe for consistency with an older experiment, maybe newly designed. Grammatical orthography ("ktiv dikduki") is a good stand-by, as its application to foreign words is defined poorly if at all.
An option Witztum has used with place names before is to replace
final heys by alephs. He would probably try that here.
(The result in fact improves a little, to 145281/million.)
As a simple example, take the "Son to Matityah" sample set in [WRR3]. The header is Ben Le'Matityah (son to Matityah), and the reasonable related expressions are the names of his five sons. It scores a modest but respectable 194/million. However, Witztum is not content with that so he builds up the fire with some additional words, chosen for the sole reason that they make the result better. Alongside the names of Matityah's sons, he writes three expressions that describe Matityah himself (not his sons). They are "son of Yochanan", and two spellings of "high priest". Besides the obvious fact that they don't belong at all with the names of the sons, or even with the heading (which is not "Matityah" but "son to Matityah"), there are a huge number of other words that could have been used in place of those three. For example, he could have added some important words that do fit into the list, like Hashmonean, Maccabees, and The Maccabees. He didn't, because they would have made the result 13 times worse.
One might reply to this, "Isn't 194/million pretty remarkable anyway?" The answer is "no". First consider the header phrase "son to Matityah". We can see from [WRR3] that he also tried "son of Matityah", but he doesn't tell us what a terrible score it gets (659393/million). He also doubtless tried the simple headers "Matityah" and ""Matityahu" (the more common way of writing his name) but they are dismal failures too. He also tried two ways of measuring the significance level. Then there was the choice of writing one son's name only as Yonatan or also as Yehonatan (which he did). We are already up to 3/1000, without even considering the most important choice. The most important choice was the choice of topic. Witztum had previously conducted a very extensive investigation of Chanukah-related words. A considerable amount of such material appears in his book [Wit]. Out of the thousands of possible Chanukah-related experiments that he could have done, Witztum selected one that worked.
In the sub-camps experiment Witztum could add some very good Auschwitz-related words with a minimum of effort. Already years ago he tried a large number of possibilities, and presented the winners in his book [Wit]. They appear there in pictures clustered around the very same expression Be'Auschwitz.
A lesser but significant weapon in the Witztum arsenal is the practice of modifying the experimental method. There are some alternate measurement methods mentioned in the preprints of [WRR1] involving the details of the distance calculation. The decision was invariably made in the favourable direction.
Another possibility is to allow 4-letter words. Witztum's papers [WRR1-3] all disallow them, but we can see from his Chanukah experiment that this rule is one he is quite happy to break if it suits him.
Some extra variations invented by Witztum are mentioned in [Witmac]. The first is to perturb the letters of the second word only, and not those of the first word. The other he calls "BEST". Both variations give the famous rabbis experiment [WRR1] a worse result, despite Witztum's claim to the contrary. (See [Witmac] for the details.) They don't help here either, producing 316532/million and 366389/million, respectively, and 452105/million in combination. However, they might help after the data has been manipulated.
Maybe Witztum has used an entirely new variation. We have no way to know until he tells us.
It is not possible for us to say exactly how Witztum has turned 289149/million into 1/million, but there is no doubt that the freedom of movement he has utilised in the past could be successfully utilised here, too.
Once one has some choices that can be made, 1/million is not very small at all. On average you need twenty 1-in-2 decisions, or ten 1-in-4 decisions. There are far more than that available just along the well-trodden paths that we have mentioned here, and there are many other paths. After making the most advantageous choices, the only remaining task is to hide them inside some rhetoric carefully constructed to fool the credulous reader into believing the lie. We can hardly wait to see what crap Witztum has cooked up this time - just don't expect us to eat it.
Several demonstrations of data manipulation have been made using the text of War and Peace. Readers are invited to discover the many choices we deliberately made in their production.
This page was primarily written by Brendan McKay. I wish to thank the various colleagues who assisted with matters of Hebrew and Polish. I dedicate this page to the millions of victims whose memory should be invoked in the cause of truth, not in the service of deception.
Back to the Torah Codes page