| Febrl - Freely extensible biomedical record linkage |
| Febrl - Freely extensible biomedical record linkage |
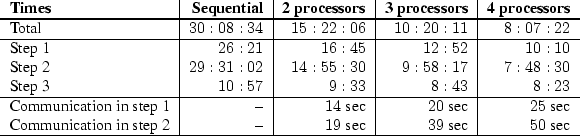
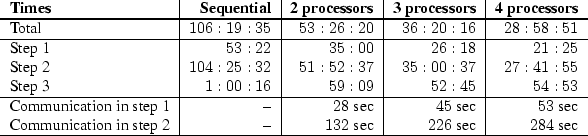
To give an idea on the performance of Febrl we present timing results of experiments we made on our computing platform, a SUN Enterprise 450 shared memory (SMP) server with four 480 MHz Ultra-SPARC II processors and 4 Giga Bytes of main memory.
We were running deduplication processes with ![]() ,
, ![]() and
and
![]() records from a health data set containing midwife data
records provided by the NSW Department of Health. This data set
has earlier been standardised into a clean form and is stored as a CSV
(comma separated values) text file. Six field comparison functions
were used and the classical blocking index technique with three
indexes (passes) was applied. The standard Fellegi and Sunter
classifier with a lower threshold value of
records from a health data set containing midwife data
records provided by the NSW Department of Health. This data set
has earlier been standardised into a clean form and is stored as a CSV
(comma separated values) text file. Six field comparison functions
were used and the classical blocking index technique with three
indexes (passes) was applied. The standard Fellegi and Sunter
classifier with a lower threshold value of ![]() and an upper
threshold value of
and an upper
threshold value of ![]() was used to classify the record pairs, and
finally a one-to-one assignment procedure was applied.
was used to classify the record pairs, and
finally a one-to-one assignment procedure was applied.
We ran these deduplication tasks using a varying number of processors (1, 2, 3 and 4) and the achieved results are shown in tables 2.1, 2.2, 2.3 and 2.4 in the form hh:mm:ss or mm:ss, respectively. Step 1 denotes the loading for records and building of the indexes, step 2 the actual deduplication and step 3 the one-to-one assignment and saving the result into text files. Time spent for communication is given in seconds.
A closer look at the results shows that parallel processing of
Febrl results in almost linear speedup,
i.e. running Febrl on two processors means the run time is
reduced by a factor of two, and on four processors the same task is
around ![]() times faster than on one processor. The results also show
that the dominating factor is the comparison of record pairs, which
unfortunately is not linearly scalable with the number of records. The
increase in records from
times faster than on one processor. The results also show
that the dominating factor is the comparison of record pairs, which
unfortunately is not linearly scalable with the number of records. The
increase in records from ![]() to
to ![]() (10-fold) results in a
record pair comparison time increased by a factor of around thirty.
(10-fold) results in a
record pair comparison time increased by a factor of around thirty.
Table 2.5 shows the maximal amount of memory used by the various Febrl test runs. Similarly to the increased run times, the amount of memory needed increases more than linearly. A ten-fold increase in the number of records results in a fifteen-fold increase in the amount of memory needed. Additionally, parallel processing in Febrl also results in an increased amount of memory needed, which is due to the replication of various data structures on the parallel Febrl processes.
These timing and memory results given here are just examples on the performance of Febrl on a particular platform given a particular data set and performing deduplication as defined in an example project file. Potential users should note that many factors influence the performance of Febrl, including the definition of the standardisation, blocking indexes and linkage or deduplication processes, as well as the given computing platform and data sets.
| Febrl - Freely extensible biomedical record linkage |