|
Yi Li Ph.D student, ECE Dept, University of Maryland liyi AT umiacs DOT umd DOT edu |
|

|
Past Research
|
|
|
6 |
|
Combining Motion from Texture and Lines for Visual Navigation Two novel methods for computing 3D structure information from video for a piecewise planar scene are presented. The first method is based on a new line constraint, which clearly separates the estimation of distance from the estimation of slant. The second method exploits the concepts of phase correlation to compute from the change of image frequencies of a textured plane, distance and slant information. The two different estimates together with structure estimates from classical image motion are combined and integrated over time using an extended Kalman filter. The estimation of the scene structure is demonstrated experimentally in a motion control algorithm that allows the robot to move along a corridor. We demonstrate the efficacy of each individual method and their combination and show that the method allows for visual navigation in textured as well as un-textured environments. Paper: Bitsakos, K.; Li Yi; Fermuller, C., "Combining motion from texture and lines for visual navigation," Intelligent Robots and Systems, 2007. IROS 2007. IEEE/RSJ International Conference on , vol., no., pp.232-239, Oct. 29 2007-Nov. 2 2007 |
|
|
||
|
5 |
|
Efficiently Determining
Silhouette Consistency Volume intersection is a frequently used
technique to solve the Shape-From-Silhouette problem, which constructs a 3D
object estimate from a set of silhouettes taken with calibrated cameras. It
is natural to develop an efficient algorithm to determine the consistency of
a set of silhouettes before performing time-consuming reconstruction, so that
inaccurate silhouettes can be omitted. In this paper we first present a fast
algorithm to determine the consistency of three silhouettes from known (but
arbitrary) viewing directions, Paper: Y. Li, D.W. Jacobs, "Efficiently
Determining Silhouette Consistency," CVPR '07., vol., no.,
pp.1-8, 17-22 June 2007 |
|
|
||
|
4 |
|
Object
Detection Using A Shape Codebook This paper presents a method for detecting categories of objects in real-world images. Given training images of an object category, our goal is to recognize and localize instances of those objects in a candidate image. The main contribution of this work is a novel structure of the shape codebook for object detection. A shape codebook entry consists of two components: a shape codeword and a group of associated vectors that specify the object centroids. Like their counterpart in language, the shape codewords are simple and generic such that they can be easily extracted from most object categories. The associated vectors store the geometrical relationships between the shape codewords, which specify the characteristics of a particular object category. Thus they can be considered as the ``grammar'' of the shape codebook. In this paper, we use Triple-Adjacent-Segments (TAS) extracted from image edges as the shape codewords. Object detection is performed in a probabilistic voting framework. Experimental results on public datasets show performance similar to the state-of-the-art, yet our method has significantly lower complexity and requires considerably less supervision in the training (We only need bounding boxes for a few training samples, do not need figure/ground segmentation and do not need a validation dataset). Paper: X. Yu, Y. Li, C. Fermuller, and D. Doermann , "Object Detection Using A Shape Codebook," British Machine Vision Conference '07. Sep 2007 |
|
|
||
|
3 |
|
Language
Identification for Handwritten Language identification for handwritten document images is an open document analysis problem. In this paper, we propose a novel approach to language identification for documents containing mixture of handwritten and machine printed text using image descriptors constructed from a codebook of shape features. We encode local text structures using scale and rotation invariant codewords, each representing a segmentation-free shape feature that is generic enough to be detected repeatably. We learn a concise, structurally indexed shape codebook from training by clustering and partitioning similar feature types through graph cuts. Our approach is easily extensible and does not require skew correction, scale normalization, or segmentation. We quantitatively evaluate our approach using a large real-world document image collection, which is composed of 1,512 documents in eight languages (Arabic, Chinese, English, Hindi, Japanese, Korean, Russian, and Thai) and contains a complex mixture of handwritten and machine printed content. Experiments demonstrate the robustness and flexibility of our approach, and show exceptional language identification performance that exceeds the state of the art.
Learning Visual Shape Lexicon for Document Developing effective content recognition methods for diverse imagery continues to challenge computer vision researchers. We present a new approach for document image content categorization using a lexicon of shape features. Each lexical word corresponds to a scale and rotation invariant shape feature that is generic enough to be detected repeatably and segmentation free. We learn a concise, structurally indexed shape lexicon from training by clustering and partitioning feature types through graph cuts. We demonstrate our approach on two challenging document image content recognition problems: 1) The classification of 4, 500 Web images crawled from Google Image Search into three content categories — pure image, image with text, and document image, and 2) Language identification of 8 languages (Arabic, Chinese, English, Hindi, Japanese, Korean, Russian, and Thai) on a 1, 512 complex document image database composed of mixed machine printed text and handwriting. Our approach is capable to handle high intra-class variability and shows results that exceed other state-of-the-art approaches, allowing it to be used as a content recognizer in image indexing and retrieval systems. Papers: G. Zhu, X. Yu, Y, Li, and D. Doermann, Language identification for handwritten document images using a shape codebook. Pattern Recogn. 42, 12 (Dec. 2009), 3184-3191. G. Zhu, X. Yu, Y, Li, and D. Doermann, Learning Visual Shape Lexicon for Document Image Content Recognition. ECCV'08. |
|
|
||
|
2 |
|
Script-Independent Text Line Segmentation in Freestyle Handwritten Documents
In this paper, we propose a novel approach based on density estimation and a state-of-the-art image segmentation technique, the level set method. From an input document image, we estimate a probability map, where each element represents the probability that the underlying pixel belongs to a text line. The level set method is then exploited to determine the boundary of neighboring text lines by evolving an initial estimate. Unlike most connected component based methods [1, 2], the proposed algorithm does not use any script-specific knowledge. Extensive quantitative experiments on freestyle handwritten documents with diverse scripts, such as Arabic, Chinese, Korean, and Hindi, demonstrate that our algorithm consistently outperforms previous methods [3, 1, 2]. Further experiments show the proposed algorithm is robust to scale change, rotation, and noise.
Papers:
Y. Li, Y. Zheng, D. Doermann, and S. Jaeger, "Script-Independent Text Line Segmentation in Freestyle Handwritten Documents," IEEE Trans on Pattern Anal. and Mach. Intell, vol. 30, no. 8, pp. 1313-1329, August, 2008.
Y. Li, Y. Zheng, and D. Doermann, "Detecting Text
Lines in Handwritten Documents," ICPR'06, vol. 2, pp.
1030-1033.
Y. Li, Y. Zheng, and D.
Doermann, "A New Algorithm for Detecting Text Line in Handwritten
Documents" Intl. Conf. on Frontiers in Handwriting Recognition.
pp. 35-40, 2006 Public Dataset: Chinese, Korean, and Hindi dataset |
|
|
||
|
1 |
|
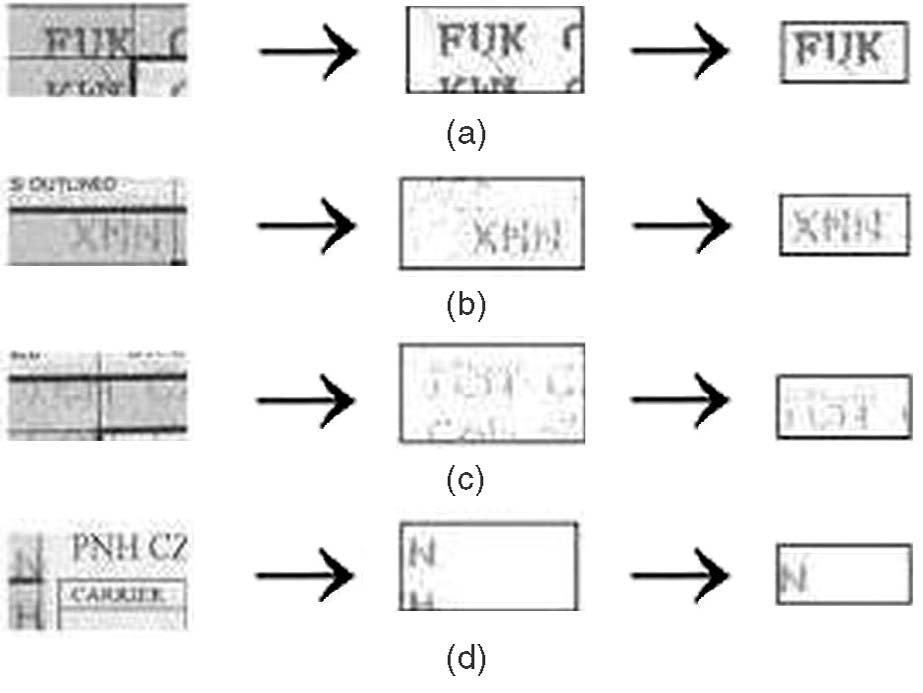
Correlation has been used extensively in object detection field. In this paper, two kinds of correlation filters, Minimum Average Correlation Energy (MACE) and Extended Maximum Average Correlation Height (EMACH), are applied as adaptive shift locators to detect and locate smudgy character strings in complex tabular color flight coupon images. These strings in irregular tabular coupon are computer-printed characters but of low contrast and could be shifted out of the table so that we cannot detect and locate them using traditional algorithms. In our experiment, strings are extracted in the preprocessing phase by removing background and then based on geometric information, two correlation filters are applied to locate expected fields. We compare results from two correlation filters and demonstrate that this algorithm is a high accurate approach. Paper: Y. Li, Z. Wang, H. Zeng, "Correlation Filter: An Accurate Approach to Detect and Locate Low Contrast Character Strings in Complex Table Environment," IEEE Trans on Pattern Anal. and Mach. Intell, vol. 26, no. 12, pp. 1639-1644, December, 2004. |