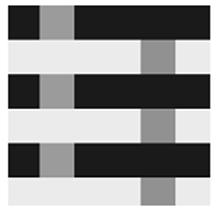|
Yi Li Ph.D student, ECE Dept, University of Maryland liyi AT umiacs DOT umd DOT edu |
|

|
Current Research
|
|
|
A.1 |
|
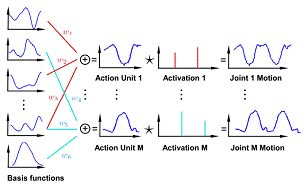
Movement Synergies for Cognitive Robots Part of my work focuses on decomposing motion capture (MoCap) sequences into synergies (smooth and short basis functions) along with the times at which they are “activated” for each joint. Given MoCap sequences, I proposed an algorithm to automatically learn the synergies as well as the activations using L1 Minimization, a novel optimization technique that aims at recovering the exact sparse solution by minimizing the L1 norm (sum of absolute value) of the variables instead of the traditional sum of squared errors. Human actions by their nature are sparse both in action space domain and time domain. They are sparse in action space, because different actions share similar movements on some joints. They are sparse in the time domain, because we do not want much overlap of the individual movements on a single joint. Two recent developed tools in machine learning, namely the Orthogonal Matching Pursuit and the Split Bregman Algorithm, enabled us to alternately solve two large convex minimizations and learn the synergies and the activations simultaneously. Experiments demonstrate the power of the decomposition as a tool for representing and classifying human movements in the MoCap sequences. The activations of the synergies characterize the underlying rhythm in the parts of the bodies, and the weights of the synergies are effective for action retrieval and recognition. Particularly, the representation allows us to substantially compress novel MoCap data, which is fundamentally invariant to the sampling rate. Experiments further suggest that our approach is well suited for early diagnosis of motion disorder diseases (e.g., Parkinson's disease), an emerging issue in public health. Currently we are recording more data to confirm our findings. Paper: Y. Li, C. Fermuller, and Y. Aloimonos, ``Learning Shift-Invariant Sparse Representation of Actions'', To appear in Computer Vision and Pattern Recognition (CVPR) 2010. |
|
|
||
|
A.2 |
|
Assessing Human Health
One of my goals is to work towards improving human health, especially with regard to aging and various disorders or conditions that exhibit themselves through movement (neuron degenerative diseases, rehabilitation, etc). The study of human movement is important to diagnose neuron degenerative diseases because movement is a window into nervous system functions. However, current computational approaches have been limited in their abilities to represent unrestricted full-body motion and to learn the intrinsic features for diagnosis and assessment of human action. My research focuses on measuring human action, understanding its coordination characteristic, and further developing optimal diagnostic and intervention tools for populations with atypical movement patterns. This newly emerging field of interpreting human behavior has many new applications to motion disorder diagnosis and rehabilitation, and the National Institutes of Health already has several calls for research on the topic. My research consists of two major components: representing motion signals and relating them to cognitive systems. To build a compact and effective representation of motion data, I concentrated on the concept of synergies and their activations, which assist the recognition, synthesis, and coordination of human actions (see also Movement Synergies). Further, I strive to answer some high level cognitive questions, including determining the influence within a dynamical network of actions (see also Coordinaed Actions).
I have worked on Parkinson’s disease data. We showed that motion sequences can be decomposed into synergies along with the times at which they are “activated” for each joint. The activations are sparse in time and explicitly express the coordination among different joints. Thus, a person tends to have the motion disorder problem if there are large misalignments among the activation signals.
In the future, I plan to work on early diagnosis of developmental diseases on the basis of human movement (e.g., Autism). I am primarily interested in the assessment of the effect of the medicine for the motion disorder diseases. This will accelerate the diagnosis procedure and provide a quantitative evaluation for the rehabilitation process. |
|
|
||
|
|
|
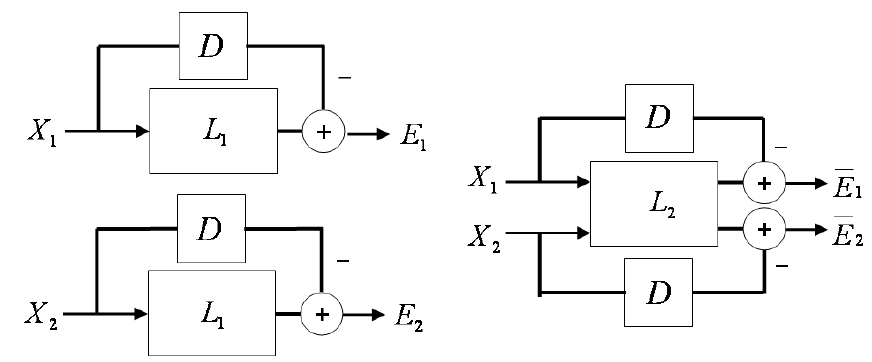
Among cognitive studies on human body movements, social coordination has gained more attention than others because human beings in any society have complex behaviors to coordinate themselves and interact with the real world for defensive, living and hunting purposes. In fact, recent scientific studies suggest that the “action mirroring neurons”, which map an action in the visual space to its embodiment in the motoric space, might be tuned to social coordination rather than single action mirroring. Thus, it is very clear that the knowledge of social action coordination will be helpful for understanding the functionalities of the mirroring mechanism of human action, and will eventually result in efficient estimation of appropriate actions in response or in modifying behaviors online. In the project, we attempt to establish a theory for studying the influence in a group of coordinated actions using the concept of Mirror Neurons in neuroscience. Suggested by Prof. Fadiga and Dr.Alessandro D'Ausilio, w proposed to use Granger Causality as a tool to study the coordinated actions performed by at least two units. In Granger Causality, actions are modeled by autoregressive processes, and the causality is framed in terms of predictability. If one action causes the other, then knowledge (history) of the first action should help predict future values of the latter (smaller error residual).
We successfully applied Granger Causality to the kinematic data in a chamber orchestra to test the interaction among players and between conductors and players. As an extremely interesting case of the mirror-like mechanism, the motor systems in musicians support their orchestrated musical execution. We discovered that a good conductor drives the orchestra more frequently than an amateur conductor, with a stronger driving force on average for all players in each piece of music. We plan to apply the above theory to dancers and sport games to study the dynamical network of coordination.
Paper (in preparation): ---, ``Coordinated Actions in Music'', In preparation for Science Magazine. |
|
|
||
|
|
|
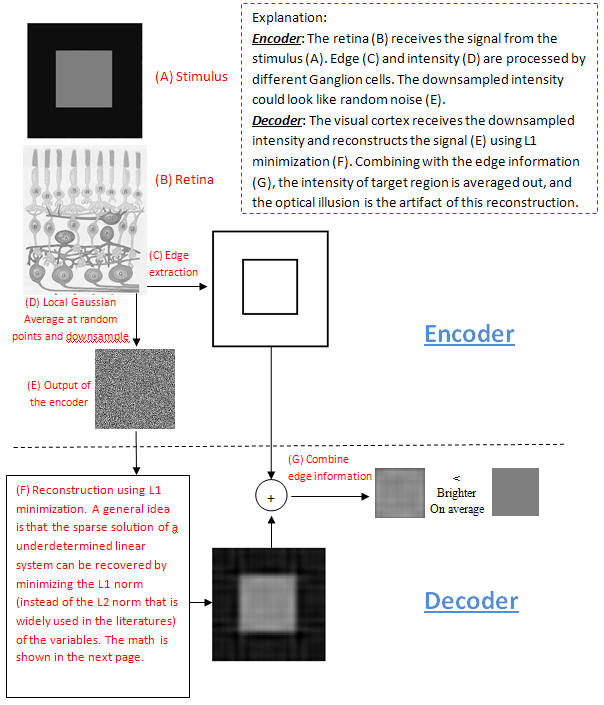
Visual Illusions A cognitive system needs to understand the underlying mathematics which tells it how to actively sample and reconstruct a real-world scene that is sparse or compressible. I proposed to use the new theory of compressive sensing as the model. At the retina the intensity signal is compressed by random sampling locally averaged values. In the cortex the intensity values are reconstructed from the down-sampled signal, and combined with the edges. Reconstruction amounts to solving an underdetermined linear equation system. Assuming that the intensity signal is sparse in the Fourier domain, the sparse reconstructed signal deviates from the original signal, and the reconstruction error can explain many well-known lightness illusions including the dilemma between contrast and assimilation. We illustrate the processing as follows:
Papers: Y. Li, C. Fermuller and Y. Aloimonos, ``Illusory lightness perception due to signal compression and reconstruction'', To appear in Vision Science Society (VSS) Conference 2010. |
|
|
||
|
|
|
My goal is to extract key poses for effective action recognition for robot-human interaction. It is well believed that not all poses are created equal, but much of the previous work largely focused on the recognition algorithms, and ignored to address the pose extraction sufficiently. We model the key poses as the discontinuities in the second order derivatives of the latent variables in the reduced visual space which we obtain using the Gaussian Process Dynamical Models (GPDM). Experiments demonstrate that the extracted key poses are consistent under different conditions, such as subject variation, video quality, frame rate, and camera motion, and robust to viewpoint change. This facilitates the human action analysis and improves the action recognition rate significantly by reducing the uncharacteristic poses both in the training and the test sets. The results are also helpful in psychological experiments for action understanding.
|
|
|
||
|
|
Recognition Result |
Semantic Robot Vision for Intelligent Service Robots Intelligent service robots must search, identify and further interact with objects just from their names like humans do. However, despite the tremendous progress on robotics, current systems still cannot fully perform this task automatically. A cognitive robot should bridge this semantic gap and eventually assist human beings in everyday’s life. This is the fundamental motivation that we participate in the Semantic Robot Vision Challenge. Quote from the challenge rules: " Teams provide their own robot hardware and software. The robots will be in the room one at a time. The robots must be able to navigate safely in the indoor setting without damaging the room or the objects within it in the event of an inadvertent collision. ..... A textual list of 20 objects will be given to the agents. This list will consist of both generally-named objects, such as "shoes" or "umbrella", and specifically-named objects, such as a book that has a specific title. To encourage the use of 3D information from images, the generally-named objects are divided further into two groups, according to when they are announced to the teams." We implement a prototype system on a mobile platform that uses laser sensors for simultaneously localization and mapping (SLAM). Our system parses the large amount of the semantic information available online, automatically searches image examples of those objects and learns visual models, and actively segments and locates the objects using a quad camera system on a pan-tilt-unit in a previous unknown environment.
Team Website: http://www.umiacs.umd.edu/research/SRVC/index.htm Paper (in preparation): Y. Li, M. Nishigaki, K. Bitsakos, C. Fermuller and Y. Aloimonos, ``A Cognitive Robot for Intelligent Service'', In preparation for Intl. J. of Robot. Res. (IJRR). |