 |
 |
 |
Febrl - Freely extensible biomedical record linkage |
 |
 |
 |
Approximate string comparison is an important feature for successful
weight calculation when comparing strings from names and addresses.
Instead of simply having an agreement or disagreement weight returned,
approximate string comparators allow for partial agreement if strings
are not exactly but almost the same, which can be due to typographical
and other errors.
Various algorithms for approximate string comparisons have been
developed, in both the statistical record linkage [30] and in
the computer science and natural language processing communities. In
the Febrl system, several approximate string comparison
algorithms are implemented in the module
stringcmp.py. All string comparison functions implemented in
this module return a value between  (two strings are completely
different) and
(two strings are completely
different) and  (two strings are the same).
(two strings are the same).
The approximate string comparison method has to be selected with the
compare_method argument. The following methods are currently
implemented:
jaro
The Jaro [30,37] string comparator is commonly
used in record linkage software. It computes the number of
common characters in two strings, the lengths of both strings,
and the number of transpositions to compute a similarity measure
between and .
winkler
The Winkler comparator is based on the Jaro
comparator but takes into account the fact that typographical
errors occur more often towards the end of words, and thus gives
an increased value to characters in agreement at the beginning
of the strings. The partial agreement weight is therefore
increased if the beginning of two strings is the same.
bigram
Bigrams are the two-character substrings in a string, for
example 'peter' contains the bigrams 'pe',
'et', 'te' and 'er'. In the Bigram
string comparator, the number of common bigrams in the two
strings is counted and divided by the average number of bigrams
in the two strings, to calculate a similarity measure between
0.0 and 1.0.
editdist
The edit distance (also known as Levenshtein distance)
algorithm counts the minimum number of character deletions,
transpositions and insertions that have to be made to
transform one string into the other. This number is then divided
by the length of the longer string to get a similarity measure
between 0.0 and 1.0.
bagdist
The bag distance is a cheap distance measure [2] which
always returns a distance smaller or equal to the edit distance.
For two given strings 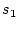 and
and 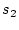 this distance can be
calculated in
this distance can be
calculated in
 , while the edit distance
takes
, while the edit distance
takes
 to calculate. The bag
distance is then divided by the length of the longer string to
get a similarity measure between 0.0 and 1.0. Due to this
transformation the bag distance similarity measure will always
be larger than the edit distance similarity measure.
to calculate. The bag
distance is then divided by the length of the longer string to
get a similarity measure between 0.0 and 1.0. Due to this
transformation the bag distance similarity measure will always
be larger than the edit distance similarity measure.
seqmatch
This approximate string comparator is implemented in the Python
standard library difflib. It is based on an algorithm
developed by Ratcliff and Obershelp in the 1980s,
and uses pattern matching to compute a similarity measure
between 0.0 and 1.0.
compression
Using compression algorithms to calculate similarity between
strings has recently been proposed [9,18] and used
for various data mining algorithms, including clustering and
time series analysis. A similarity measure between two strings
and is calculated as follows.
with 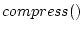 being the compression function available in
the Python module zlib.
being the compression function available in
the Python module zlib.
sortwinkler
If a string contains more than one word (i.e. it contains at least one
whitespace), then the words are first sorted before a standard
Winkler comparison is applied. The idea is that - unless there
are errors in the first few letters of a word - sorting of swapped words
will bring them into the same order, thereby improving the similarity
value.
permwinkler
Based on the experience that swapped words result in low approximate
similarity measure for most string comparators, the permutation
Winkler creates all possible permutations of words (if there are more
than one word in an input string, and then calculates the similarity
measures - using the standard Winkler comparator discussed above
- for all permutations. The maximum calculated similarity measure is
returned.
A second argument that needs to be given to the approximate string
comparator is min_approx_value (a number between and
), which is the minimal approximate string similarity measure
tolerated.
If the two strings are the same (i.e. if the similarity measure
returned by the approximate string comparator is ), the agreement
weight is returned. If the value is less than but larger or
equal to min_approx_value, then a partial agreement weight is
calculated using the following formula.
If the returned value is smaller than min_approx_value the
disagreement weight will be returned.
If a frequency table is given for this field comparator, the agreement
weight will be calculated using the frequency of the value in the
input fields that are compared, as described in
Section 9.2.1. Frequency dependent weights
will also be used to calculate a partial agreement weight.
Release 0.3.1, documentation updated on July 1, 2005.

