DIRECT-ADDRESS-SEARCH
1 return
DIRECT-ADDRESS-INSERT
1
DIRECT-ADDRESS-DELETEWhen is large, and , the set of all the actual keys, is small, a lot of space is wasted in direct addressing. In many applications, is very large relative to . An example is a database index. If we are indexing a 32-bit integer column, we will need one slot for each possible integer, in the case of 32-bit, that's over 4 billion slots! Even in a large database, with one million rows, we are still only using 0.025% of our table to index that column. Furthermore, each integer in that column has to be unique in order for the direct address table to work. A solution to this is using hash tables.
1 NIL
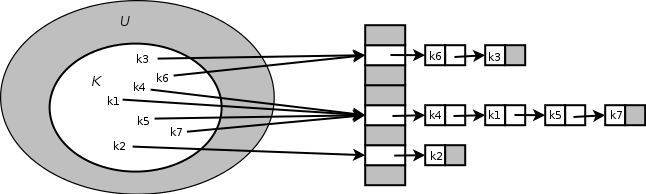
CHAINED-HASH-SEARCH
1 Search for an element with key in list
CHAINED-HASH-INSERT
1 Insert at the head of list
CHAINED-HASH-DELETE
1 Delete from the list
Theorem: In a hash table in which collisions are resolved by chaining, an unsuccessful search (or a successful search) takes time under the assumption of simple uniform hashing - all elements are equally likely to hash into any slot, independently of where any other element has been hashed into.
HASH-INSERT
1
2 repeat
3 if
4 then
5 return
6 else
7 until
8 error "Hash table overflow."
HASH-SEARCH
1
2 repeat
3 if
4 then return
5
6 until or
7 return NIL

